letztes Update: 26.03.2021
Heute möchte ich Euch erklären, wie ich bei meiner Nextcloud-Installation die neue Suche „Fulltextsearch“ eingerichtet habe. Fulltextsearch ersetzt damit die bisherige erweiterte Suche Nextant. Mit beiden Plugins ist es möglich, PDF Dateien Bilddateien zu durchsuchen und daraus Index Dateien zu erstellen.
Damit das ganze läuft sind ein paar Schritte in der SSH Konsole notwendig und die ganze Prozedur ist in ca. 20 Minuten abgeschlossen.
Auf geht’s!
Packetquellen aktualisieren und ELS herunterladen
Als erstes müssen die Packetquellen angepasst und ein paar Dateien installiert werden.
Schritt 1:
sudo apt-get install openjdk-8-jre
curl -L -O https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.12.0.deb
sudo dpkg -i elasticsearch-7.12.0.deb sudo /etc/init.d/elasticsearch startoder
apt install elasticsearchJetzt wird ein Plugin für Elasticsearch heruntergeladen und installiert.
Dazu diesen Downloadlink besuchen und den Link zur letzten Version per Email zukommen lassen. (aktuell Version 7.12.0)
Den Link aus der Email nun kopieren und folgendes Kommando ausführen.
cd /usr/share/elasticsearch
bin/elasticsearch-plugin install file:///pfad/zur/readonlyrest-7.12.0.zipoder
bin/elasticsearch-plugin install file:///httplink/zur/datei/readonylrest-7.12.0.zipHinweis: Nach jedem Update muss dieser Schritt wiederholt werden. Erst das Elasticsearch Update machen, dann readonlyrest deinstallieren, installieren. Das gleiche mit ingest-attachment.
bin/elasticsearch-plugin remove ingest-attachment
bin/elasticsearch-plugin remove readonlyrestKonfigurationsdatei erstellen
Nach der Installation muss eine Datei erstelltHinweis: Nach jedem Update muss dieser Schritt wiederholt werden. Erst das Elasticsearch Update machen, dann readonlyrest deinstallieren, installieren. Das gleiche mit ingest-attachment. werden, damit Fulltextsearch mit Elasticsearch kommunizieren kann.
vim /etc/elasticsearch/readonlyrest.yml
readonlyrest:
access_control_rules:
- name: erlaubt nur der Cloud zugriff auf cloud_index
groups: ["cloud"]
indices: ["cloud_index"]
users:
- username: cloudIndex
auth_key: cloudIndex:SuperPassword #dieser Eintrag kommt in die Cloud
groups: ["cloud"] X Pack Security einrichten
Nach einem Update auf Elasticsearch 6.3.1 musste ich in der Datei /etc/elasticsearch/elasticsearch.yml
xpack.security.enabled: false
einfügen, damit das ganze wieder starten konnte.
Zuvor war der Log damit gefüllt und Nextcloud gab mir die Meldung aus „no Alive Clusters“
[2018-07-10T07:55:43,681][INFO ][t.b.r.c.s.SettingsPoller ] [CLUSTERWIDE SETTINGS] Cluster not ready... [2018-07-10T07:55:44,682][INFO ][t.b.r.c.s.SettingsPoller ] [CLUSTERWIDE SETTINGS] Cluster not ready...Quelle:forum.readonlyrest.com
Maximale RAM Nutzung einstellen
Damit nicht Java mehr RAM als nötig blockiert kann man die Default Einstellungen überschreiben. Hier gilt die Regel nicht mehr als 50% des maximal verfügbaren RAM auf dem System. Bei sind es 32 GB gesamt, also 16 Gb RAM im Maximum. Da aber noch andere Prozesse laufen auf dem Server habe ich diesen Wert runter gesetzt auf 8GB.
nano /etc/elasticsearch/jvm.options.d/jvm.optionsDarin folgendes eintragen, und Elasticsearch neu starten.
-Xms8g
-Xmx8gSollte dann so aus sehen im Terminal
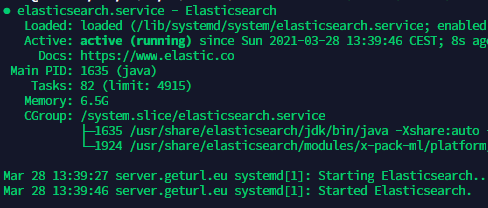
Notiz:
Denkt hier auch einen Nutzernamen aus und ersetzt „username“ mit diesem. Das gleiche gilt für das Passwort. Generiert euch eins (am besten mit pwgen -a -y 12) und setzt dieses für password ein.
In diesem Beispiel oben wird eine Cloud konnektiert mit Elasticsearch.
Ingest Attachment installieren
Zum Schluss wird noch ein Plugin zum indexieren von PDF Dateien installiert:
sudo bin/elasticsearch-plugin install ingest-attachmentEditiert in der /etc/elasticsearch/elasticsearch.yml den Host und ändert diesen in eure IP Adresse des Servers.
abschliessend noch die Logdatei beschreibbar machen sonst startet Elasticsearch nicht.
chown -R elasticsearch:elasticsearch /var/log/elasticsearchStartet anschließend Elasticsearch neu damit die Änderungen übernommen werden.
service elasticsearch restartKontrolliert abschließend ob Elasticsearch auf den Port 9200 und Java auf Port 9300 lauscht.
netstat - tulpn | grep 9200
netstat - tulpn | grep 9300Zurück in der Cloud müssen alle 3 Plugins installiert und aktiviert werden.
Im Appstore zu finden unter Werkzeuge
[!][](/content/images/wordpress/2018/01/bildschirmfoto-vom-2018-01-23-12-35-11.png)
In der Nextcloud FTS konfigurieren
In den Einstellungen von FullTextSearch im Feld „Adress of Servlet:“ dies eintragen: (Hier brauchen wir den Nutzernamen und das Passwort aus der readonlyrest.yml Datei)
http://cloudIndex:SuperPassword@localhost:9200/unter Index tragen wir folgendes ein:
my_index
Damit wäre die Installation fertig und es lässt sich nun der Index starten mit: (Hinweis: php8.0 wird nicht unterstützt beim Index. Index mit php7.4 -f starten)
sudo - u www-data php occ fulltextsearch:indexNach dem ersten kompletten Index werden alle neuen Dateien automatisch indexiert.
Wenn euch was auffällt was nicht passt, oder hier irgendwo hängen bleibt, schreibt es in die Kommentare, würde mich freuen ?
Installation via Docker-compose und Docker
Alternativ ist auch ein Setup in Docker Containern möglich. Erstellt zuerst ein Verzeichnis, bei mir ist es /opt/docker-ncsearch
sudo mkdir -p /opt/docker-ncsearchDanach wird in diesem Ordner eine YML und ein Dockerfile erstellt. mit folgendem Inhalt.
sudo vi /opt/docker-ncsearch/Dockerfile
FROM docker.elastic.co/elasticsearch/elasticsearch:7.12.0
RUN bin/elasticsearch-plugin install --batch ingest-attachmentalternativ:
Das sorgt dafür, dass das Image immer basierend auf elasticsearch:7.11.0 ist und ein Plugin (ingest-Attachment) installiert wird.
Als nächstes wird das File docker-compose.yml erstellt.
echo "vm.max_map_count=262144" & & /etc/sysctl.conf & & sysctl -p curl -L https://github.com/docker/compose/releases/download/$(curl -Ls https://www.servercow.de/docker-compose/latest.php)/docker-compose-$(uname -s)-$(uname -m) > /usr/local/bin/docker-compose & & chmod +x /usr/local/bin/docker-compose mkdir -p /opt/docker-ncsearch & & cd /opt/docker-ncsearchDocker-compose.yml anpassen
Damit Daten erhalten bleiben sollten ein paar Pfade angepasst werden in der docker-comose.yml.
Unter enviroment „ES_JAVA_OPTS=-Xms750m -Xmx750m“ hinzufügen und unter volumes den Pfad anpassen wo die Daten gespeichert werden sollen.
version: '2.2'
services:
elasticsearch1:
build: ./elasticsearch
container_name: esnode1
restart: always
environment:
- cluster.name=ncsearch
- bootstrap.memory_lock=true
- discovery.type=single-node
- "ES_JAVA_OPTS=-Xms750m -Xmx750m"
- "network.host=0.0.0.0"
ulimits:
memlock:
soft: -1
hard: -1
# location for persistent data
volumes:
- /opt/docker-ncsearch/nc-data/:/usr/share/elasticsearch/data
ports: # make elasticsearch reachable on the host itself, when Nextcloud running on the host
- "127.0.0.1:9200:9200"
expose: # make elasticsearch reachable in the internal docker network
- "9200" # direct elasticsearch connection
networks:
ncsearch-network:
ipv4_address: 172.22.2.235
aliases:
- elasticsearch1
[...]Quelle: Telegram Nextcloud Gruppe
Nun das File mit docker-compose up -d asuführen.
Achließend müsste Fulltextsearch mit allem drum und dran laufen und auf den Port lauschen.
Ihr könnt nun mein Setup bei github herunterladen!

Quelle: Github